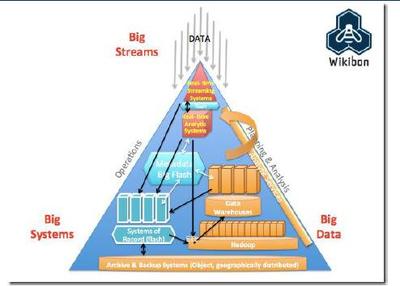
在當今數字化浪潮中,數據已成為驅動社會進步與經濟發展的核心要素。大數據的興起,正是得益于其背后三大基礎技術支柱——計算、存儲與分析技術的持續演進與成熟。這些技術相互促進,共同構建了支撐海量數據處理與應用的技術底座。
一、計算技術:從集中到分布,從通用到專用
計算技術是大數據處理的引擎。早期,數據處理主要依賴于大型機或高性能服務器的集中式計算。隨著數據量的爆炸式增長,這種模式在可擴展性和成本上遇到了瓶頸。以Hadoop MapReduce、Spark為代表的分布式計算框架應運而生,它們能夠將計算任務分解并分發到成百上千臺普通服務器組成的集群中并行處理,極大地提升了數據處理能力。
計算技術進一步向異構和專用化發展。圖形處理器(GPU)、張量處理單元(TPU)等專用硬件被廣泛應用于機器學習、深度學習等對算力要求極高的數據分析場景,顯著加速了模型訓練與推理過程。云計算提供的彈性計算資源,使得企業能夠按需獲取近乎無限的計算能力,降低了大數據應用的門檻。
二、存儲技術:容量、性能與成本的平衡藝術
存儲技術負責承載海量數據。傳統的關系型數據庫在面對非結構化、半結構化數據以及高并發讀寫時顯得力不從心。分布式文件系統(如HDFS)和NoSQL數據庫(如HBase、Cassandra、MongoDB)的成熟,解決了海量數據存儲與高可擴展性的問題。它們能夠在廉價硬件上構建起可靠的存儲集群,并通過數據分片、副本機制保障數據的安全與可用性。
對象存儲(如Amazon S3、阿里云OSS)因其極高的擴展性、耐用性和低成本,已成為存儲海量靜態數據(如圖片、視頻、日志)的事實標準。新硬件如固態硬盤(SSD)、非易失性內存(NVM)的普及,以及存儲與計算分離架構的流行,都在持續優化著數據存取的性能與成本結構。
三、分析技術:從離線批處理到實時智能洞察
分析技術是大數據價值變現的關鍵。早期大數據分析主要以Hadoop MapReduce為代表的離線批處理為主,處理延遲通常在小時甚至天級別。Apache Spark憑借其內存計算優勢,將批處理性能提升了一個量級。
業務對實時性的追求催生了流計算技術的快速發展,如Apache Flink、Apache Storm和Spark Streaming,它們能夠對持續不斷的數據流進行毫秒級到秒級的處理與分析,使得實時風控、實時推薦等應用成為可能。
更重要的是,分析技術正與人工智能深度融合。機器學習平臺和深度學習框架(如TensorFlow、PyTorch)的成熟,使得從大數據中挖掘復雜模式、進行預測和決策變得更為高效和普及。交互式查詢引擎(如Presto、ClickHouse)則讓用戶能夠以接近傳統數據庫的速度對海量數據進行即席查詢與分析。
四、計算機軟硬件的協同進化
大數據技術的成熟離不開底層計算機軟硬件的協同進化。在硬件層面,多核CPU、大內存容量、高速網絡(如RDMA)以及前述的GPU、SSD等,為數據處理提供了強大的物理基礎。在軟件層面,虛擬化、容器化(如Docker、Kubernetes)技術實現了資源的精細化管理和高效調度;而各類開源大數據軟件構成的龐大生態系統,則加速了技術的迭代與創新。
****
計算、存儲、分析三大基礎技術的不斷成熟與融合,以及軟硬件的協同優化,共同推動大數據技術棧日趨完善和高效。從離線到實時,從感知到智能,大數據技術正不斷突破性能、規模和易用性的邊界,賦能千行百業的數字化轉型,挖掘數據中蘊含的無限價值。隨著量子計算、存算一體等新技術的探索,大數據的基礎技術體系將繼續演進,迎接更大規模、更復雜場景的挑戰。